
复杂度分析
复杂度分析,我一般叫它马后炮,事后统计法。我们需要一个不用具体的测试数据来测试,就可以粗略地估计算法的执行效率的方法。
复杂度一般使用大 O 复杂度表示法,用于粗略计算代码的执行时间。
比如:
func Count(key []int) int{
var count int // 第2行
for _,v := range key{ // 第3行
count += v // 第4行
}
return count // 第6行
}计算切片里的数据的和,这段代码其实就是 读数据-运算-写数据。
可以具体分析下, 第二行代码执行了1次,第三行代码执行了 n 次(假设key 切片有 n 个数据),第四行执行了 n 次,第六行执行了一次,那么总的执行时间为:(2n+2)一条代码的执行时间。也就是总的执行时间与每行代码的执行次数成正比。我们一般的把总执行时间标为T(n),一个代码执行的时间叫 unit_time。那么上述的 T(n) = (2n+2) unit_time。
注意:这个 T(n) 并不是复杂度。
尽管我们不知道 unit_time 的具体值,但是通过代码执行时间的推导过程,我们可以得到一个非常重要的规律,那就是,所有代码的执行时间 T(n) 与每行代码的执行次数 n 成正比。
因此, 我们的 T(n) = O(f(n))
其中,T(n) 我们已经讲过了,它表示代码执行的时间;n 表示数据规模的大小;f(n) 表示每行代码执行的次数总和。因为这是一个公式,所以用 f(n) 来表示。公式中的 O,表示代码的执行时间 T(n) 与 f(n) 表达式成正比。
所以,例子中的 T(n) = O(2n+2)。这就是大 O 时间复杂度表示法。大 O 时间复杂度实际上并不具体表示代码真正的执行时间,而是表示代码执行时间随数据规模增长的变化趋势,所以,也叫作渐进时间复杂度(asymptotic time complexity),简称时间复杂度。
时间复杂度分析
只关注循环执行次数最多的一段代码
大 O 这种复杂度表示方法只是表示一种变化趋势。我们通常会忽略掉公式中的常量、低阶、系数,只需要记录一个最大阶的量级就可以了。所以,我们在分析一个算法、一段代码的时间复杂度的时候,也只关注循环执行次数最多的那一段代码就可以了。这段核心代码执行次数的 n 的量级,就是整段要分析代码的时间复杂度。
比如刚刚的例子里,第三和和第四行被执行了n次,所以总时间复杂度是O(n)
加法法则:总复杂度等于量级最大的那段代码的复杂度
我们魔改下刚刚的例子:
函数里有三个循环体,第一段执行了100次,第二段执行了n次,第三段执行了 n*n 次。
这里需要注意的是,即便这段代码循环 10000 次、100000 次,只要是一个已知的数,跟 n 无关,照样也是常量级的执行时间。当 n 无限大的时候,就可以忽略。
如果但看第2和第3段循环体,他们的复杂度分别是O(n) 和 O(n^2),因此我们取其中最大的量级作为整段代码的时间复杂度 O(n^2),即,总的时间复杂度就等于量级最大的那段代码的时间复杂度。
如果 T1(n)=O(f(n)),T2(n)=O(g(n));那么 T(n)=T1(n)+T2(n)=max(O(f(n)), O(g(n))) =O(max(f(n), g(n))).
乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
如果 T1(n)=O(f(n)),T2(n)=O(g(n));那么 T(n)=T1(n) T2(n)=O(f(n)) O(g(n))=O(f(n) * g(n)).
也就是说,假设 T1(n) = O(n),T2(n) = O(n^2),则 T1(n) * T2(n) = O(n^3)。落实到具体的代码上,我们可以把乘法法则看成是嵌套循环,比如刚刚的第三段循环体。
复杂度量级
常见的复杂度量级有下面这几种:

O(1)
O(1) 只是常量级时间复杂度的一种表示方法,并不是指只执行了一行代码。
即使上面执行了三行,这样代码的时间复杂度我们都记作 O(1)。或者说,一般情况下,只要算法中不存在循环语句、递归语句,即使有成千上万行的代码,其时间复杂度也是Ο(1)。
O(logn)、O(nlogn)
对数阶时间复杂度非常常见,同时也是最难分析的一种时间复杂度。
显然第二、三行执行的次最多,所以只要计算出这两行执行的次数就知道了整个代码的复杂度。
我们可以设:执行次数为 x,那么当 2^x > n 时,则跳出循环体,所以 x 趋近于 log_2(n),因此该代码发时间复杂度为O(log_2(n))
同理,看看下面的代码:
这段代码的时间复杂度为 O(log_3(n))。
实际上,不管是以 2 为底、以 3 为底,还是以 10 为底,我们可以把所有对数阶的时间复杂度都记为 O(logn)。因为我们可以通过换底公式实现转换 log3n 就等于 log_3(2) * log_2(n)。基于我们前面的一个理论:在采用大 O 标记复杂度的时候,可以忽略系数,即 O(Cf(n)) = O(f(n))。我们忽略对数的“底”,统一表示为 O(logn)。
那 O(nlogn) 就很容易理解了。如果一段代码的时间复杂度是 O(logn),我们循环执行 n 遍,时间复杂度就是 O(nlogn) 了。而且,O(nlogn) 也是一种非常常见的算法时间复杂度。比如,归并排序、快速排序的时间复杂度都是 O(nlogn)。
O(m+n)、O(m*n)
从代码中可以看出,m 和 n 是表示两个数据规模。我们无法事先评估 m 和 n 谁的量级大,所以我们在表示复杂度的时候,就不能简单地利用加法法则,省略掉其中一个。所以,上面代码的时间复杂度就是 O(m+n)。
针对这种情况,原来的加法法则就不正确了,我们需要将加法规则改为:T1(m) + T2(n) = O(f(m) + g(n))。但是乘法法则继续有效:T1(m)T2(n) = O(f(m) f(n))。 同理 O(m*n) 也是如此。
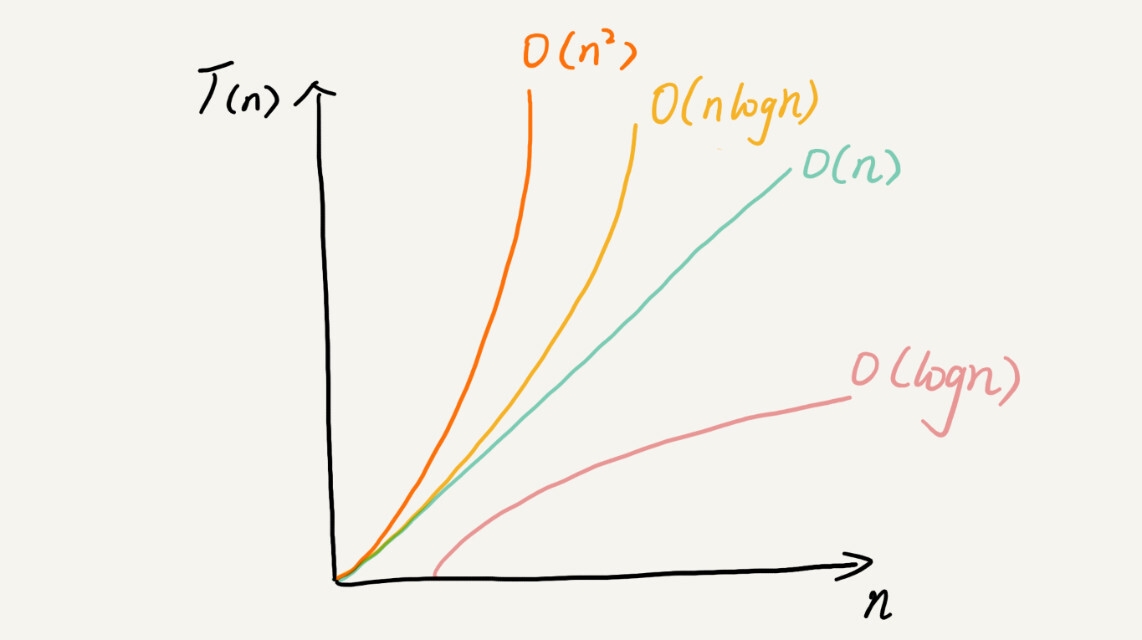
我们可以对比着看看不同量级的增速:
空间复杂度分析
空间复杂度全称就是渐进空间复杂度(asymptotic space complexity),表示算法的存储空间与数据规模之间的增长关系。
第 3 行申请了一个大小为 m+n 的 int 的 map,除此之外,剩下的代码都没有占用更多的空间,所以整段代码的空间复杂度就是 O(m+n)。
我们常见的空间复杂度就是 O(1)、O(n)、O(n2),像 O(logn)、O(nlogn) 这样的对数阶复杂度平时都用不到。而且,空间复杂度分析比时间复杂度分析要简单很多。所以,对于空间复杂度,掌握刚我说的这些内容已经足够了。
总结
复杂度也叫渐进复杂度,包括时间复杂度和空间复杂度,用来分析算法执行效率与数据规模之间的增长关系,可以粗略地表示,越高阶复杂度的算法,执行效率越低。常见的复杂度并不多,从低阶到高阶有:O(1)、O(logn)、O(n)、O(nlogn)、O(n2)。
最后更新于