
Bufio
bufio是“buffered I/O”的缩写。顾名思义,这个代码包中的程序实体实现的 I/O 操作都内置了缓冲区。
bufio包中的数据类型主要有:Reader;Scanner;Writer和ReadWriter。
与io包中的数据类型类似,这些类型的值也都需要在初始化的时候,包装一个或多个简单 I/O 接口类型的值。(这里的简单 I/O 接口类型指的就是io包中的那些简单接口。)
bufio.Reader类型值中的缓冲区
bufio.Reader类型的值(以下简称Reader值)内的缓冲区,其实就是一个数据存储中介,它介于底层读取器与读取方法及其调用方之间。所谓的底层读取器,就是在初始化此类值的时候传入的 io.Reader 类型的参数值。
Reader 值的读取方法一般都会先从其所属值的缓冲区中读取数据。同时,在必要的时候,它们还会预先从底层读取器那里读出一部分数据,并暂存于缓冲区之中以备后用。
有这样一个缓冲区的好处是,可以在大多数的时候降低读取方法的执行时间。虽然,读取方法有时还要负责填充缓冲区,但从总体来看,读取方法的平均执行时间一般都会因此有大幅度的缩短。
bufio.Reader类型并不是开箱即用的,因为它包含了一些需要显式初始化的字段。为了让你能在后面更好地理解它的读取方法的内部流程,我先在这里简要地解释一下这些字段,如下所示。
buf:[]byte类型的字段,即字节切片,代表缓冲区。虽然它是切片类型的,但是其长度却会在初始化的时候指定,并在之后保持不变。
rd:io.Reader类型的字段,代表底层读取器。缓冲区中的数据就是从这里拷贝来的。
r:int类型的字段,代表对缓冲区进行下一次读取时的开始索引。我们可以称它为已读计数。
w:int类型的字段,代表对缓冲区进行下一次写入时的开始索引。我们可以称之为已写计数。
err:error类型的字段。它的值用于表示在从底层读取器获得数据时发生的错误。这里的值在被读取或忽略之后,该字段会被置为nil。
lastByte:int类型的字段,用于记录缓冲区中最后一个被读取的字节。读回退时会用到它的值。
lastRuneSize:int类型的字段,用于记录缓冲区中最后一个被读取的 Unicode 字符所占用的字节数。读回退的时候会用到它的值。这个字段只会在其所属值的ReadRune方法中才会被赋予有意义的值。在其他情况下,它都会被置为-1。
bufio包为我们提供了两个用于初始化Reader值的函数,分别叫:NewReader;NewReaderSize;
它们都会返回一个 *bufio.Reader 类型的值。NewReader 函数初始化的 Reader 值会拥有一个默认尺寸的缓冲区。这个默认尺寸是 4096 个字节,即:4 KB。而NewReaderSize函数则将缓冲区尺寸的决定权抛给了使用方。
由于这里的缓冲区在一个 Reader 值的生命周期内其尺寸不可变,所以在有些时候是需要做一些权衡的。NewReaderSize 函数就提供了这样一个途径。
在bufio.Reader类型拥有的读取方法中,Peek方法和ReadSlice方法都会调用该类型一个名为fill的包级私有方法。fill方法的作用是填充内部缓冲区。
fill方法会先检查其所属值的已读计数。如果这个计数不大于0,那么有两种可能。
一种可能是其缓冲区中的字节都是全新的,也就是说它们都没有被读取过,另一种可能是缓冲区刚被压缩过。
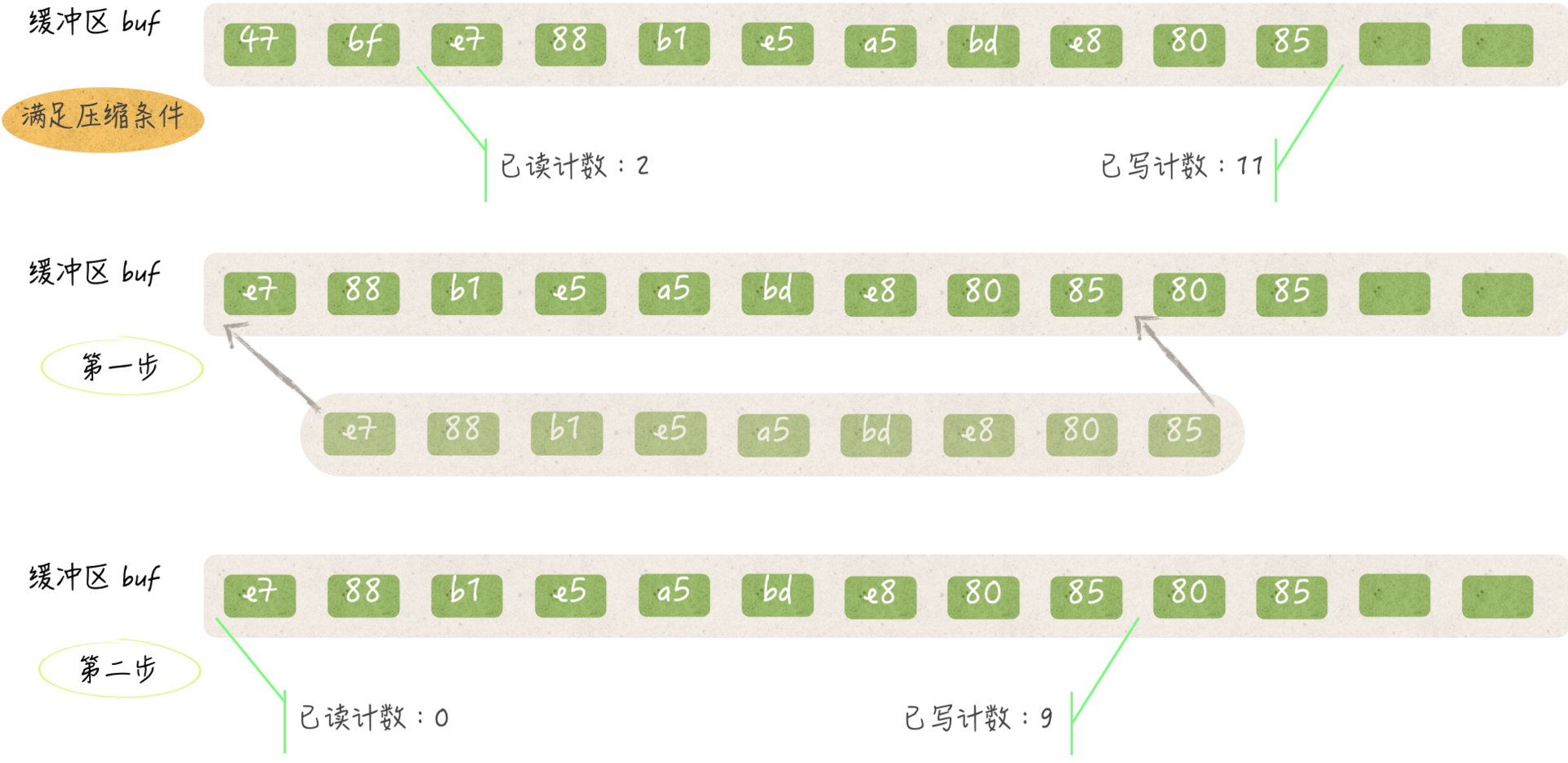
对缓冲区的压缩包括两个步骤。
第一步,把缓冲区中在[已读计数, 已写计数)范围之内的所有元素值(或者说字节)都依次拷贝到缓冲区的头部。
比如,把缓冲区中与已读计数代表的索引对应字节拷贝到索引0的位置,并把紧挨在它后边的字节拷贝到索引1的位置,以此类推。这一步之所以不会有任何副作用,是因为已读计数之前的字节都已经被读取过,并且肯定不会再被读取了,因此把它们覆盖掉是安全的。在压缩缓冲区之后,已写计数之后的字节只可能是已被读取过的字节,或者是已被拷贝到缓冲区头部的未读字节,又或者是代表未曾被填入数据的零值0x00。所以,后续的新字节是可以被写到这些位置上的。
在压缩缓冲区的第二步中,fill方法会把已写计数的新值设定为原已写计数与原已读计数的差。这个差所代表的索引,就是压缩后第一次写入字节时的开始索引。
该方法还会把已读计数的值置为0。显而易见,在压缩之后,再读取字节就肯定要从缓冲区的头部开始读了。
fill方法只要在开始时发现其所属值的已读计数大于0,就会对缓冲区进行一次压缩。之后,如果缓冲区中还有可写的位置,那么该方法就会对其进行填充。
在填充缓冲区的时候,fill方法会试图从底层读取器那里,读取足够多的字节,并尽量把从已写计数代表的索引位置到缓冲区末尾之间的空间都填满。
在这个过程中,fill方法会及时地更新已写计数,以保证填充的正确性和顺序性。另外,它还会判断从底层读取器读取数据的时候,是否有错误发生。如果有,那么它就会把错误值赋给其所属值的err字段,并终止填充流程。
bufio.Writer 缓冲数据
bufio.Writer类型字段:
err:error类型的字段。它的值用于表示在向底层写入器写数据时发生的错误。
buf:[]byte类型的字段,代表缓冲区。在初始化之后,它的长度会保持不变。
n:int类型的字段,代表对缓冲区进行下一次写入时的开始索引。我们可以称之为已写计数。
wr:io.Writer类型的字段,代表底层写入器。
bufio.Writer 类型有一个名为Flush的方法,它的主要功能是把相应缓冲区中暂存的所有数据,都写到底层写入器中。数据一旦被写进底层写入器,该方法就会把它们从缓冲区中删除掉。
删除有时候只是逻辑上的删除而已。不论是否成功地写入了所有的暂存数据,Flush方法都会妥当处置,并保证不会出现重写和漏写的情况。该类型的字段n在此会起到很重要的作用。
bufio.Writer类型值(以下简称Writer值)拥有的所有数据写入方法都会在必要的时候调用它的Flush方法。
Write方法有时候会在把数据写进缓冲区之后,调用Flush方法,以便为后续的新数据腾出空间。WriteString方法的行为与之类似。
又比如,WriteByte方法和WriteRune方法,都会在发现缓冲区中的可写空间不足以容纳新的字节,或 Unicode 字符的时候,调用Flush方法。
此外,如果Write方法发现需要写入的字节太多,同时缓冲区已空,那么它就会跨过缓冲区,并直接把这些数据写到底层写入器中。
而ReadFrom方法,则会在发现底层写入器的类型是io.ReaderFrom接口的实现之后,直接调用其ReadFrom方法把参数值持有的数据写进去。
在通常情况下,只要缓冲区中的可写空间无法容纳需要写入的新数据,Flush方法就一定会被调用。并且,bufio.Writer类型的一些方法有时候还会试图走捷径,跨过缓冲区而直接对接数据供需的双方。
bufio.Reader 读取数据
bufio.Reader类型拥有很多用于读取数据的指针方法,这里面有 4 个方法可以作为不同读取流程的代表,它们是:Peek、Read、ReadSlice和ReadBytes。
Reader值的Peek方法的功能是:读取并返回其缓冲区中的n个未读字节,并且它会从已读计数代表的索引位置开始读。
在缓冲区未被填满,并且其中的未读字节的数量小于n的时候,该方法就会调用fill方法,以启动缓冲区填充流程。但是,如果它发现上次填充缓冲区的时候有错误,那就不会再次填充。
如果调用方给定的n比缓冲区的长度还要大,或者缓冲区中未读字节的数量小于n,那么Peek方法就会把“所有未读字节组成的序列”作为第一个结果值返回。
同时,它通常还把“bufio.ErrBufferFull变量的值(以下简称缓冲区已满的错误)”
作为第二个结果值返回,用来表示:虽然缓冲区被压缩和填满了,但是仍然满足不了要求。只有在上述的情况都没有出现时,Peek方法才能返回:“以已读计数为起始的n个字节”和“表示未发生任何错误的nil”。
bufio.Reader类型的 Peek 方法有一个鲜明的特点,那就是:即使它读取了缓冲区中的数据,也不会更改已读计数的值。
这个类型的其他读取方法并不是这样。就拿该类型的Read方法来说,它有时会把缓冲区中的未读字节,依次拷贝到其参数p代表的字节切片中,并立即根据实际拷贝的字节数增加已读计数的值。
在缓冲区中还有未读字节的情况下,该方法的做法就是如此。不过,在另一些时候,其所属值的已读计数会等于已写计数,这表明:此时的缓冲区中已经没有任何未读的字节了。
当缓冲区中已无未读字节时,Read方法会先检查参数p的长度是否大于或等于缓冲区的长度。如果是,那么Read方法会索性放弃向缓冲区中填充数据,转而直接从其底层读取器中读出数据并拷贝到p中。这意味着它完全跨过了缓冲区,并直连了数据供需的双方。
Peek方法在遇到类似情况时的做法与这里的区别(这两种做法孰优孰劣还要看具体的使用场景)。
Peek方法会在条件满足时填充缓冲区,并在发现参数n的值比缓冲区的长度更大时,直接返回缓冲区中的所有未读字节。
如果我们当初设定的缓冲区长度很大,那么在这种情况下的方法执行耗时,就有可能会比较长。最主要的原因是填充缓冲区需要花费较长的时间。
由fill方法执行的流程可知,它会尽量填满缓冲区中的可写空间。然而,Read方法在大多数的情况下,是不会向缓冲区中写入数据的,尤其是在前面描述的那种情况下,即:缓冲区中已无未读字节,且参数p的长度大于或等于缓冲区的长度。
此时,该方法会直接从底层读取器那里读出数据,所以数据的读出速度就成为了这种情况下方法执行耗时的决定性因素。
当然了,我在这里说的只是耗时操作在某些情况下更可能出现在哪里,一切的结论还是要以性能测试的客观结果为准。
在Read方法的内部流程,如果缓冲区中已无未读字节,但其长度比参数p的长度更大,那么该方法会先把已读计数和已写计数的值都重置为0,然后再尝试着使用从底层读取器那里获取的数据,对缓冲区进行一次从头至尾的填充。这里的尝试只会进行一次。无论在这一时刻是否能够获取到数据,也无论获取时是否有错误发生,都会是如此。而fill方法的做法与此不同,只要没有发生错误,它就会进行多次尝试,因此它真正获取到一些数据的可能性更大。
这两个方法有一点是相同,那就是:只要它们把获取到的数据写入缓冲区,就会及时地更新已写计数的值。
ReadSlice方法和ReadBytes方法, 这两个方法的功能总体上来说,都是持续地读取数据,直至遇到调用方给定的分隔符为止。
ReadSlice方法会先在其缓冲区的未读部分中寻找分隔符。如果未能找到,并且缓冲区未满,那么该方法会先通过调用fill方法对缓冲区进行填充,然后再次寻找,如此往复。
如果在填充的过程中发生了错误,那么它会把缓冲区中的未读部分作为结果返回,同时返回相应的错误值。注意,在这个过程中有可能会出现虽然缓冲区已被填满,但仍然没能找到分隔符的情况。
这时,ReadSlice方法会把整个缓冲区(也就是buf字段代表的字节切片)作为第一个结果值,并把缓冲区已满的错误(即bufio.ErrBufferFull变量的值)作为第二个结果值。
经过fill方法填满的缓冲区肯定从头至尾都只包含了未读的字节,所以这样做是合理的。
当然了,一旦ReadSlice方法找到了分隔符,它就会在缓冲区上切出相应的、包含分隔符的字节切片,并把该切片作为结果值返回。无论分隔符找到与否,该方法都会正确地设置已读计数的值。
比如,在返回缓冲区中的所有未读字节,或者代表全部缓冲区的字节切片之前,它会把已写计数的值赋给已读计数,以表明缓冲区中已无未读字节。
如果说ReadSlice是一个容易半途而废的方法的话,那么可以说ReadBytes方法算得上是相当的执着。
ReadBytes方法会通过调用ReadSlice方法一次又一次地从缓冲区中读取数据,直至找到分隔符为止。
在这个过程中,ReadSlice方法可能会因缓冲区已满而返回所有已读到的字节和相应的错误值,但ReadBytes方法总是会忽略掉这样的错误,并再次调用ReadSlice方法,这使得后者会继续填充缓冲区并在其中寻找分隔符。
除非ReadSlice方法返回的错误值并不代表缓冲区已满的错误,或者它找到了分隔符,否则这一过程永远不会结束。
如果寻找的过程结束了,不管是不是因为找到了分隔符,ReadBytes方法都会把在这个过程中读到的所有字节,按照读取的先后顺序组装成一个字节切片,并把它作为第一个结果值。如果过程结束是因为出现错误,那么它还会把拿到的错误值作为第二个结果值。
在bufio.Reader类型的众多读取方法中,依赖ReadSlice方法的除了ReadBytes方法,还有ReadLine方法。不过后者在读取流程上并没有什么特别之处,我就不在这里赘述了。
另外,该类型的ReadString方法完全依赖于ReadBytes方法,前者只是在后者返回的结果值之上做了一个简单的类型转换而已。
bufio.Reader类型的Peek方法、ReadSlice方法和ReadLine方法都有可能会造成内容泄露。
调用方可以通过这些方法返回的结果值访问到缓冲区的其他部分,甚至修改缓冲区中的内容。这通常都是很危险的。
最后更新于