
Go Test
单元测试,它又称程序员测试。顾名思义,这就是程序员们本该做的自我检查工作之一。
Go 语言的缔造者们从一开始就非常重视程序测试,并且为 Go 程序的开发者们提供了丰富的 API 和工具。利用这些 API 和工具,我们可以创建测试源码文件,并为命令源码文件和库源码文件中的程序实体,编写测试用例。
在 Go 语言中,一个测试用例往往会由一个或多个测试函数来代表,不过在大多数情况下,每个测试用例仅用一个测试函数就足够了。测试函数往往用于描述和保障某个程序实体的某方面功能,比如,该功能在正常情况下会因什么样的输入,产生什么样的输出,又比如,该功能会在什么情况下报错或表现异常,等等。
可以为 Go 程序编写三类测试,即:功能测试(test)、基准测试(benchmark,也称性能测试),以及示例测试(example)。示例测试严格来讲也是一种功能测试,只不过它更关注程序打印出来的内容。
一般情况下,一个测试源码文件只会针对于某个命令源码文件,或库源码文件(以下简称被测源码文件)做测试,所以我们总会(并且应该)把它们放在同一个代码包内。
测试源码文件的主名称应该以被测源码文件的主名称为前导,并且必须以“_test”为后缀。每个测试源码文件都必须至少包含一个测试函数。并且,从语法上讲,每个测试源码文件中,都可以包含用来做任何一类测试的测试函数,即使把这三类测试函数都塞进去也没有问题。我通常就是这么做的,只要把控好测试函数的分组和数量就可以了。
我们可以依据这些测试函数针对的不同程序实体,把它们分成不同的逻辑组,并且,利用注释以及帮助类的变量或函数来做分割。同时,我们还可以依据被测源码文件中程序实体的先后顺序,来安排测试源码文件中测试函数的顺序。
测试函数的名称和签名
对于功能测试函数来说,其名称必须以Test为前缀,并且参数列表中只应有一个*testing.T类型的参数声明。
对于性能测试函数来说,其名称必须以Benchmark为前缀,并且唯一参数的类型必须是*testing.B类型的。
对于示例测试函数来说,其名称必须以Example为前缀,但对函数的参数列表没有强制规定。
只有测试源码文件的名称对了,测试函数的名称和签名也对了,当我们运行go test命令的时候,其中的测试代码才有可能被运行。
go test 命令在开始运行时,会先做一些准备工作,比如,确定内部需要用到的命令,检查我们指定的代码包或源码文件的有效性,以及判断我们给予的标记是否合法,等等。
在准备工作顺利完成之后,go test 命令就会针对每个被测代码包,依次地进行构建、执行包中符合要求的测试函数,清理临时文件,打印测试结果。这就是通常情况下的主要测试流程。go test 命令会串行地执行测试流程中的每个步骤。
为了加快测试速度,它通常会并发地对多个被测代码包进行功能测试,只不过,在最后打印测试结果的时候,它会依照我们给定的顺序逐个进行,这会让我们感觉到它是在完全串行地执行测试流程。
由于并发的测试会让性能测试的结果存在偏差,所以性能测试一般都是串行进行的。更具体地说,只有在所有构建步骤都做完之后,go test命令才会真正地开始进行性能测试。
并且,下一个代码包性能测试的进行,总会等到上一个代码包性能测试的结果打印完成才会开始,而且性能测试函数的执行也都会是串行的。
功能测试结果分析
最左边的ok表示此次测试成功,也就是说没有发现测试结果不如预期的情况。
在测试结果的中间,显示的是被测代码包的导入路径。
最右边,展现的是此次对该代码包的测试所耗费的时间,这里显示的0.008s,即 8 毫秒。不过,当我们紧接着第二次运行这个命令的时候,输出的测试结果会略有不同,如下所示:
结果最右边的不再是测试耗时,而是(cached)。这表明,由于测试代码与被测代码都没有任何变动,所以go test命令直接把之前缓存测试成功的结果打印出来了。
go 命令通常会缓存程序构建的结果,以便在将来的构建中重用。我们可以通过运行go env GOCACHE命令来查看缓存目录的路径。缓存的数据总是能够正确地反映出当时的各种源码文件、构建环境、编译器选项等等的真实情况。
一旦有任何变动,缓存数据就会失效,go 命令就会再次真正地执行操作。所以我们并不用担心打印出的缓存数据不是实时的结果。go 命令会定期地删除最近未使用的缓存数据,但是,如果你想手动删除所有的缓存数据,运行一下go clean -cache命令就好了。
对于测试成功的结果,go 命令也是会缓存的。运行go clean -testcache将会删除所有的测试结果缓存。不过,这样做肯定不会删除任何构建结果缓存。
此外,设置环境变量GODEBUG的值也可以稍稍地改变 go 命令的缓存行为。
比如,设置值为gocacheverify=1将会导致 go 命令绕过任何的缓存数据,而真正地执行操作并重新生成所有结果,然后再去检查新的结果与现有的缓存数据是否一致。
如果测试失败,命令打印的结果将会是怎样的?如果功能测试函数的那个唯一参数被命名为 t,那么当我们在其中调用 t.Fail 方法时,虽然当前的测试函数会继续执行下去,但是结果会显示该测试失败。如下所示:
运行的命令与之前是相同的,但是我新增了一个功能测试函数TestFail,并在其中调用了t.Fail方法。测试结果显示,对被测代码包的测试,由于TestFail函数的测试失败而宣告失败。
对于失败测试的结果,go test命令并不会进行缓存,所以,这种情况下的每次测试都会产生全新的结果。另外,如果测试失败了,那么go test 命令将会导致:失败的测试函数中的常规测试日志一并被打印出来。
之所以显示了“main_test.go:49: Failed.”这一行,是因为我在 TestFail 函数中的调用表达式 t.Fail() 的下边编写了代码t.Log("Failed.")。 t.Log方法以及t.Logf方法的作用,就是打印常规的测试日志,只不过当测试成功的时候,go test命令就不会打印这类日志了。如果你想在测试结果中看到所有的常规测试日志,那么可以在运行go test命令的时候加入标记-v。
若我们想让某个测试函数在执行的过程中立即失败,则可以在该函数中调用t.FailNow方法。我在下面把TestFail函数中的t.Fail()改为t.FailNow()。与t.Fail()不同,在t.FailNow()执行之后,当前函数会立即终止执行。换句话说,该行代码之后的所有代码都会失去执行机会。在这样修改之后,我再次运行上面的命令,得到的结果如下:
显然,之前显示在结果中的常规测试日志并没有出现在这里。
顺便说一下,如果你想在测试失败的同时打印失败测试日志,那么可以直接调用 t.Error 方法或者 t.Errorf 方法。
前者相当于t.Log方法和t.Fail方法的连续调用,而后者也与之类似,只不过它相当于先调用了t.Logf方法。
性能测试结果分析
运行测试:
运行go test命令的时候加了两个标记。
第一个标记及其值为-bench=.,只有有了这个标记,命令才会进行性能测试。该标记的值.表明需要执行任意名称的性能测试函数,当然了,函数名称还是要符合 Go 程序测试的基本规则的。
第二个标记及其值是-run=^$,这个标记用于表明需要执行哪些功能测试函数,这同样也是以函数名称为依据的。该标记的值^$意味着:只执行名称为空的功能测试函数,换句话说,不执行任何功能测试函数。
BenchmarkGetPrimes-8被称为单个性能测试的名称,它表示命令执行了性能测试函数BenchmarkGetPrimes,并且当时所用的最大 P 数量为8。
最大 P 数量相当于可以同时运行 goroutine 的逻辑 CPU 的最大个数。这里的逻辑 CPU,也可以被称为 CPU 核心,但它并不等同于计算机中真正的 CPU 核心,只是 Go 语言运行时系统内部的一个概念,代表着它同时运行 goroutine 的能力。
顺便说一句,一台计算机的 CPU 核心的个数,意味着它能在同一时刻执行多少条程序指令,代表着它并行处理程序指令的能力。
我们可以通过调用 runtime.GOMAXPROCS函数改变最大 P 数量,也可以在运行go test命令时,加入标记-cpu来设置一个最大 P 数量的列表,以供命令在多次测试时使用。
在性能测试名称右边的是,go test命令最后一次执行性能测试函数(即BenchmarkGetPrimes函数)的时候,被测函数(即GetPrimes函数)被执行的实际次数。
go test命令在执行性能测试函数的时候会给它一个正整数,若该测试函数的唯一参数的名称为b,则该正整数就由b.N代表。我们应该在测试函数中配合着编写代码,比如:
在一个会迭代b.N次的循环中调用了GetPrimes函数,并给予它参数值1000。go test命令会先尝试把b.N设置为1,然后执行测试函数。如果测试函数的执行时间没有超过上限,此上限默认为 1 秒,那么命令就会改大b.N的值,然后再次执行测试函数,如此往复,直到这个时间大于或等于上限为止。
当某次执行的时间大于或等于上限时,我们就说这是命令此次对该测试函数的最后一次执行。这时的b.N的值就会被包含在测试结果中,也就是上述测试结果中的500000。
我们可以简称该值为执行次数,但要注意,它指的是被测函数的执行次数,而不是性能测试函数的执行次数。
最后再看这个执行次数的右边,2314 ns/op表明单次执行GetPrimes函数的平均耗时为2314纳秒。这其实就是通过将最后一次执行测试函数时的执行时间,除以(被测函数的)执行次数而得出的。

-cpu 的功能
Go 语言并发编程模型中的 P,正是 goroutine 的数量能够数十万计的关键所在。P 的数量意味着 Go 程序背后的运行时系统中,会有多少个用于承载可运行的 G 的队列存在。
每一个队列都相当于一条流水线,它会源源不断地把可运行的 G 输送给空闲的 M,并使这两者对接。
一旦对接完成,被对接的 G 就真正地运行在操作系统的内核级线程之上了。每条流水线之间虽然会有联系,但都是独立运作的。
因此,最大 P 数量就代表着 Go 语言运行时系统同时运行 goroutine 的能力,也可以被视为其中逻辑 CPU 的最大个数。而go test命令的-cpu标记正是用于设置这个最大个数的。
也许你已经知道,在默认情况下,最大 P 数量就等于当前计算机 CPU 核心的实际数量。
当然了,前者也可以大于或者小于后者,如此可以在一定程度上模拟拥有不同的 CPU 核心数的计算机。
使用-cpu标记可以模拟:被测程序在计算能力不同计算机中的表现。
标记-cpu的值应该是一个正整数的列表,该列表的表现形式为:以英文半角逗号分隔的多个整数字面量,比如1,2,4。
针对于此值中的每一个正整数,go test命令都会先设置最大 P 数量为该数,然后再执行测试函数。如果测试函数有多个,那么 go test 命令会依照此方式逐个执行。以1,2,4为例,go test命令会先以1,2,4为最大 P 数量分别去执行第一个测试函数,之后再用同样的方式执行第二个测试函数,以此类推。
go test 命令在进行准备工作的时候会读取 -cpu 标记的值,并把它转换为一个以int为元素类型的切片,我们也可以称它为逻辑 CPU 切片。
如果该命令发现我们并没有追加这个标记,那么就会让逻辑 CPU 切片只包含一个元素值,即最大 P 数量的默认值,也就是当前计算机 CPU 核心的实际数量。
在准备执行某个测试函数的时候,无论该函数是功能测试函数,还是性能测试函数,go test 命令都会迭代逻辑 CPU 切片,并且在每次迭代时,先依据当前的元素值设置最大 P 数量,然后再去执行测试函数。
-count 功能
go test 命令每一次对性能测试函数的执行,都是一个探索的过程。它会在测试函数的执行时间上限不变的前提下,尝试找到被测程序的最大执行次数。
在这个过程中,性能测试函数可能会被执行多次。为了以后描述方便,我们把这样一个探索的过程称为:对性能测试函数的一次探索式执行,这其中包含了对该函数的若干次执行,当然,肯定也包括了对被测程序更多次的执行。
说到多次执行测试函数,我们就不得不提及另外一个标记,即 -count。-count标记是专门用于重复执行测试函数的。它的值必须大于或等于0,并且默认值为1。
如果我们在运行go test命令的时候追加了-count 5,那么对于每一个测试函数,命令都会在预设的不同条件下(比如不同的最大 P 数量下)分别重复执行五次。
如果我们把前文所述的-cpu标记、-count标记,以及探索式执行联合起来看,就可以用一个公式来描述单个性能测试函数,在go test命令的一次运行过程中的执行次数,即:
性能测试函数的执行次数 = -cpu标记的值中正整数的个数 x -count标记的值 x 探索式执行中测试函数的实际执行次数
-cpu标记的值中正整数的个数 x -count标记的值 x 探索式执行中测试函数的实际执行次数对于功能测试函数来说,这个公式会更加简单一些,即:
功能测试函数的执行次数 = -cpu标记的值中正整数的个数 x -count标记的值
-cpu标记的值中正整数的个数 x -count标记的值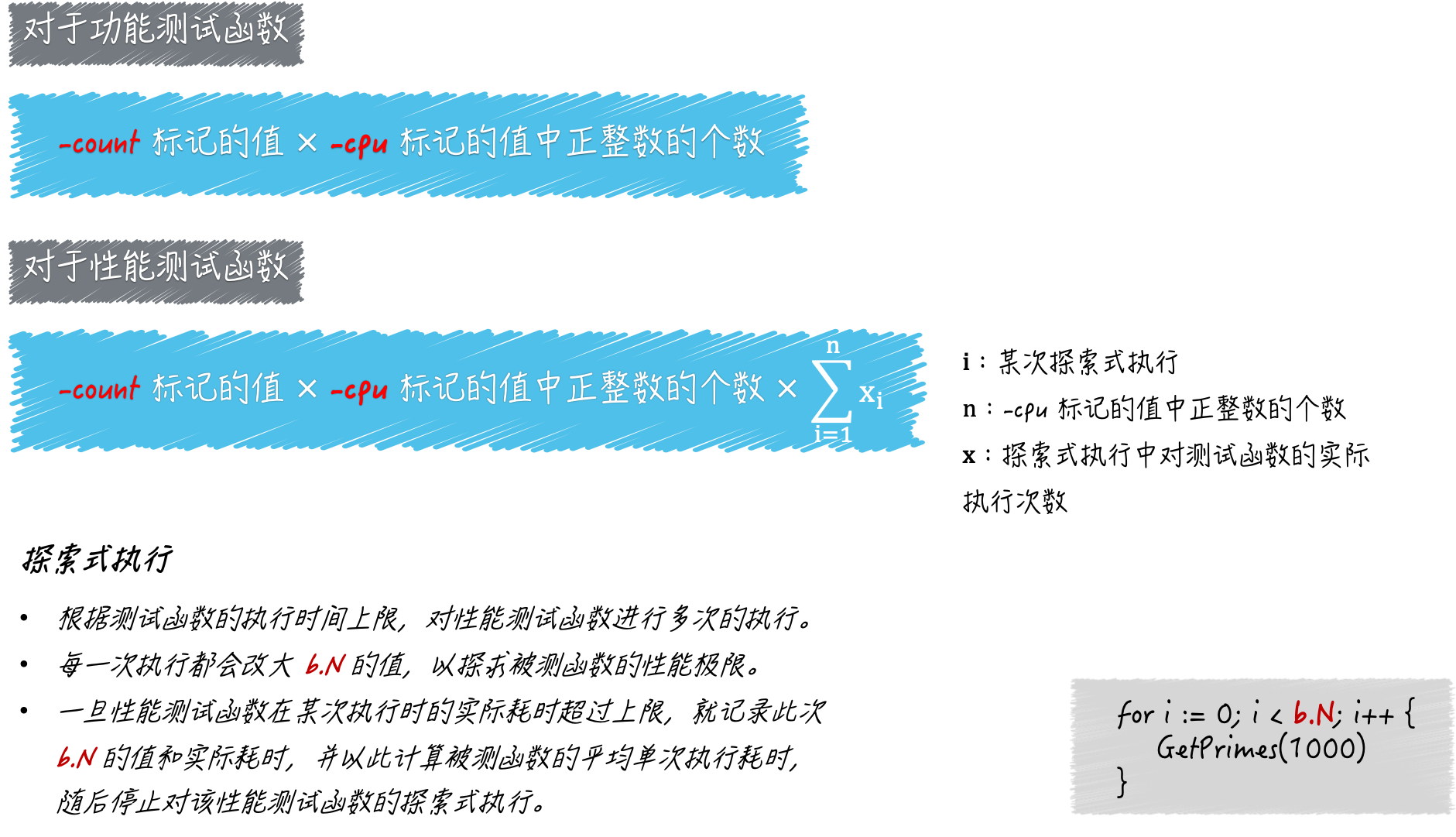
在对 Go 程序执行某种自动化测试的过程中,测试日志会显得特别多,而且好多都是重复的。
我们首先就应该想到,上面这些导致测试函数多次执行的标记和流程。我们往往需要检查这些标记的使用是否合理、日志记录是否有必要等等,从而对测试日志进行精简。
比如,对于功能测试函数来说,我们通常没有必要重复执行它,即使是在不同的最大 P 数量下也是如此。注意,这里所说的重复执行指的是,在被测程序的输入(比如说被测函数的参数值)相同情况下的多次执行。
有些时候,在输入完全相同的情况下,被测程序会因其他外部环境的不同,而表现出不同的行为。这时我们需要考虑的往往应该是:这个程序在设计上是否合理,而不是通过重复执行测试来检测风险。
还有些时候,我们的程序会无法避免地依赖一些外部环境,比如数据库或者其他服务。这时,我们依然不应该让测试的反复执行成为检测手段,而应该在测试中通过仿造(mock)外部环境,来规避掉它们的不确定性。
其实,单元测试的意思就是:对单一的功能模块进行边界清晰的测试,并且不掺杂任何对外部环境的检测。这也是“单元”二字要表达的主要含义。
相反,对于性能测试函数来说,我们常常需要反复地执行,并以此试图抹平当时的计算资源调度的细微差别对被测程序性能的影响。通过-cpu标记,我们还能够模拟被测程序在计算能力不同计算机中的性能表现。
不过要注意,这里设置的最大 P 数量,最好不要超过当前计算机 CPU 核心的实际数量。因为一旦超出计算机实际的并行处理能力,Go 程序在性能上就无法再得到显著地提升了,模拟得出的程序性能一定是不准确的。不过,这或多或少可以作为一个参考,因为,这样模拟出的性能一般都会低于程序在计算环境中的实际性能。
-parallel 功能
该标记的作用是:设置同一个被测代码包中的功能测试函数的最大并发执行数。该标记的默认值是测试运行时的最大 P 数量(这可以通过调用表达式runtime.GOMAXPROCS(0)获得)。
但是,在默认情况下,对于同一个被测代码包中的多个功能测试函数,命令会串行地执行它们。除非我们在一些功能测试函数中显式地调用t.Parallel方法。这个时候,这些包含了t.Parallel方法调用的功能测试函数就会被go test命令并发地执行,而并发执行的最大数量正是由-parallel标记值决定的。不过要注意,同一个功能测试函数的多次执行之间一定是串行的。
强调一下,-parallel标记对性能测试是无效的。当然了,对于性能测试来说,也是可以并发进行的,不过机制上会有所不同。这涉及了b.RunParallel方法、b.SetParallelism方法和-cpu标记的联合运用。
性能测试函数中的计时器
testing.B类型有这么几个指针方法:StartTimer、StopTimer和ResetTimer。这些方法都是用于操作当前的性能测试函数专属的计时器的。
所谓的计时器,是一个逻辑上的概念,它其实是testing.B类型中一些字段的统称。这些字段用于记录:当前测试函数在当次执行过程中耗费的时间、分配的堆内存的字节数以及分配次数。
这三个方法在开始记录、停止记录或重新记录执行时间的同时,也会对堆内存分配字节数和分配次数的记录起到相同的作用。
实际上,go test命令本身就会用到这样的计时器。当准备执行某个性能测试函数的时候,命令会重置并启动该函数专属的计时器。一旦这个函数执行完毕,命令又会立即停止这个计时器。
如此一来,命令就能够准确地记录下(我们在前面多次提到的)测试函数执行时间了。然后,命令就会将这个时间与执行时间上限进行比较,并决定是否在改大b.N的值之后,再次执行测试函数。
如果我们在测试函数中自行操作这个计时器,就一定会影响到这个探索式执行的结果。也就是说,这会让命令找到被测程序的最大执行次数有所不同。
函数体中先停止了当前测试函数的计时器,然后通过调用time.Sleep函数,模拟了一个比较耗时的额外操作,并且在给变量max赋值之后又启动了该计时器。
我们需要耗费额外的时间去确定max变量的值,虽然在后面它会被传入GetPrimes函数,但是,针对GetPrimes函数本身的性能测试并不应该包含确定参数值的过程。因此,我们需要把这个过程所耗费的时间,从当前测试函数的执行时间中去除掉。这样就能够避免这一过程对测试结果的不良影响了。
每当这个测试函数执行完毕后,go test命令拿到的执行时间都只应该包含调用GetPrimes函数所耗费的那些时间。只有依据这个时间做出的后续判断,以及找到被测程序的最大执行次数才是准确的。
在性能测试函数中,我们可以通过对b.StartTimer和b.StopTimer方法的联合运用,再去除掉任何一段代码的执行时间。
相比之下,b.ResetTimer方法的灵活性就要差一些了,它只能用于:去除在调用它之前那些代码的执行时间。不过,无论在调用它的时候,计时器是不是正在运行,它都可以起作用。
最后更新于